AWS EKS
You can deploy Posit Workbench on top of AWS’s EKS service. In this architecture, users can leverage the scale, reliability, and availability of AWS EKS. With a Kubernetes back-end, user sessions and jobs run in isolated Pods and potentially different base images.
An EKS-based architecture can support dozens to thousands of users, and is suitable for teams that both have experience with Kubernetes, Containers, and Helm, and also want high availability and reliability for their computational load based on demand. However, this relatively complex architecture is unnecessary for small teams with stable workloads.
Architectural overview
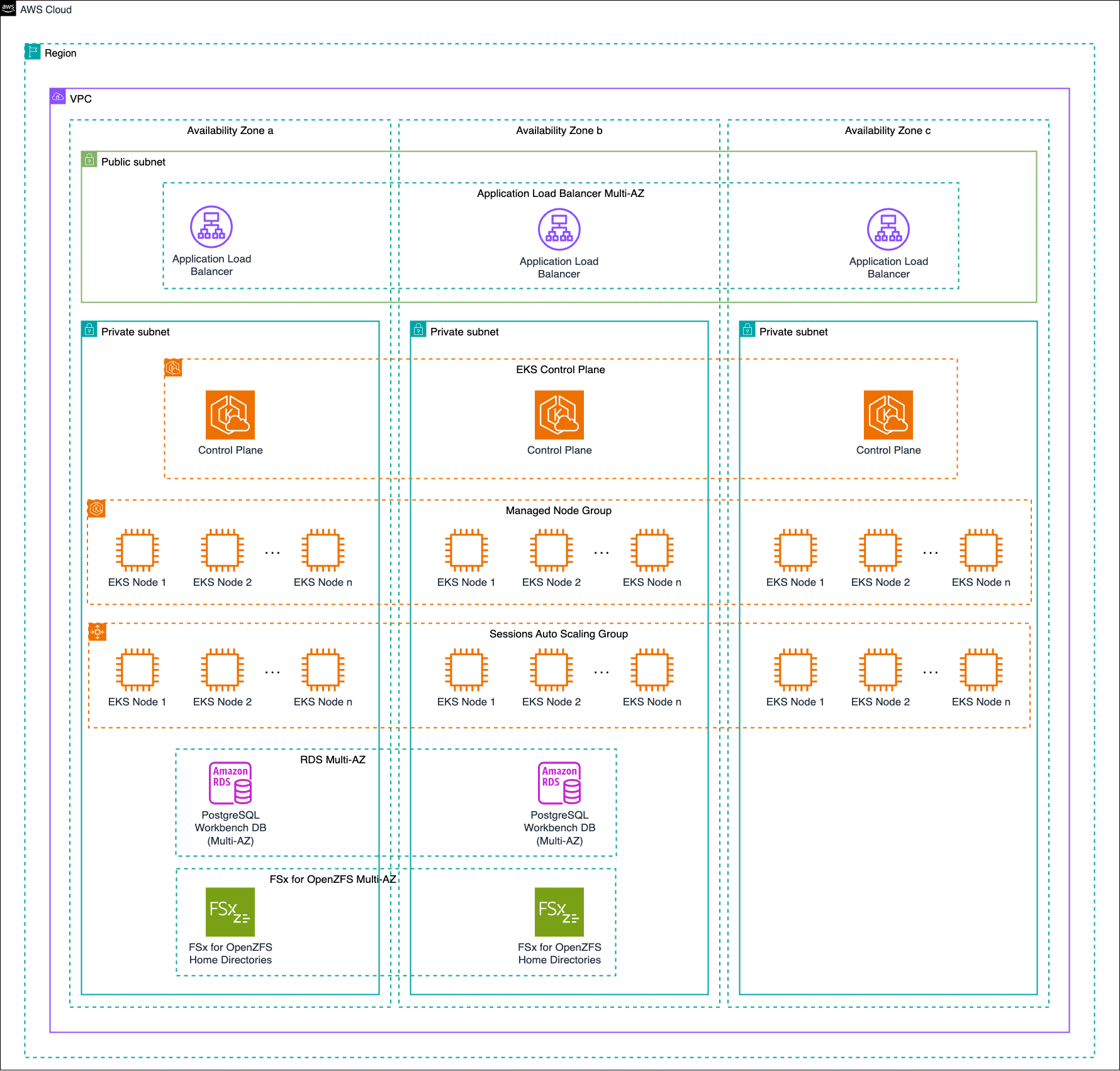
This architecture uses Helm in concert with other tools to run Posit Workbench in AWS EKS. It is recommended that it be deployed across three Availability Zones for the highest degree of availability and reliability. Posit’s public Helm charts are used to deploy Workbench into EKS alongside a Values file which will allow administrators to customize the deployment according to their needs.
AWS’s EKS includes the following as sub-components:
- An EKS Control Plane
- A Managed Node Group for persistent components, such as the main Posit Workbench server component
- A Karpenter node pool to manage autoscaling of the Workbench Session nodes
This architecture also requires the following to run Posit Workbench:
- An Application Load Balancer (ALB) with sticky sessions enabled to balance requests across the multiple Workbench Pods, spread across multiple Availability Zones
- An FSx for OpenZFS volume to store both Workbench configuration and user home directories
- This component can only be deployed in a maximum of two Availability Zones.
- An RDS PostgreSQL database to store Posit Workbench metadata
- This component can only be deployed in a maximum of two Availability Zones.
The following Helm charts need to be installed in the target EKS cluster before installing Workbench:
The minimum version of Kubernetes required for this architecture is 1.30.
Architecture diagram
Sizing and performance
Nodes
EC2 instance types should be chosen so that a number of sessions can fit on them without leaving too much infrastructure idle on average. The size and type of instances will depend on the needs and the type of workloads of the end users. For the best experience, estimate how many concurrent sessions will run at a given time and how many compute resources will be needed for each session, with a particular focus on CPU and memory. The ideal instance type to choose is one that can handle two or three such average use-case sessions at the same time.
Another important consideration is that your instance type must be able to support the largest size of session that may be run in the cluster. In most cases the t3 type instances will be insufficient. Common choices are C6i, C7i, M6i, M7i, R6i, R7i instances. The selection between C, M and R instance types should be made based on the expected memory usage per CPU core.
This architecture uses Karpenter for autoscaling. While autoscaling is not required, it is recommended for cost savings. Autoscaling with Karpenter provides the best experience over other autoscaling methods.
Karpenter allows administrators to choose multiple instance types by supplying a list of acceptable instance types to the node.kubernetes.io/instance-type label, which is a well-known label implemented by AWS. For more details, See the Karpenter documentation for Instance Types in the Node Pools chapter. More complex instance definitions can be set with combinations of well-known labels and Karpenter-specific labels.
Database
This configuration requires a PostgreSQL database for the Workbench internal database. This configuration puts little stress on the database. Up to 2,000 concurrent sessions with a db.t3.micro instance have been tested with no notable performance degradation.
Storage
For this architecture, we recommend FSx for OpenZFS instead of Regional EFS or Single Zone EFS because it offers better performance while allowing deployment in multiple Availability Zones, which increases system resiliency. FSx for Lustre is also a performant choice; however, it is not available in multiple Availability Zones.
FSx for Lustre volumes are provisioned in 1.2 TB chunks; however, this amount can be shared across all user home directories, Workbench configuration, and Workbench state storage. Workbench’s filesystem usage for configuration and state storage is modest – likely less than a few GB for a production system – therefore, the size of your FSx for Lustre volume will depend almost entirely on end-user usage patterns. Some data science teams store very little in their home directories and will only need a few GB per person. Other teams may download large files into their home directories and will need much more. Administrators should consult with their user groups to determine the appropriate size.
The choice in file system has a significant impact on the performance of the system. While we recommend using FSx for OpenZFS as the file system for this architecture, it is possible to use other file systems with Posit Workbench. FSx for Lustre is a performant choice for this architecture as well, however it is not available in multiple Availability Zones.
For more information on the performance characteristics of different file systems, see the Storage chapter of the Getting Started Guide.
Configuration details
This architecture places Workbench behind a load balancer or reverse proxy. Configure the proxy according to the instructions on the Running with a Proxy page. Workbench sessions might fail to connect or the user interface might not load correctly if the proxy is not correctly configured.
Core
Almost all of the components should be deployed inside a private subnet in each of the three AZs. The exceptions are the multi-AZ RDS and the FSx for OpenZFS volume, which can only be deployed in a maximum of two AZs. A target EKS cluster will also need to be configured. The only component that should be deployed in the public subnet is the ALB, which will provide users with access to Posit Workbench over the internet.
Networking
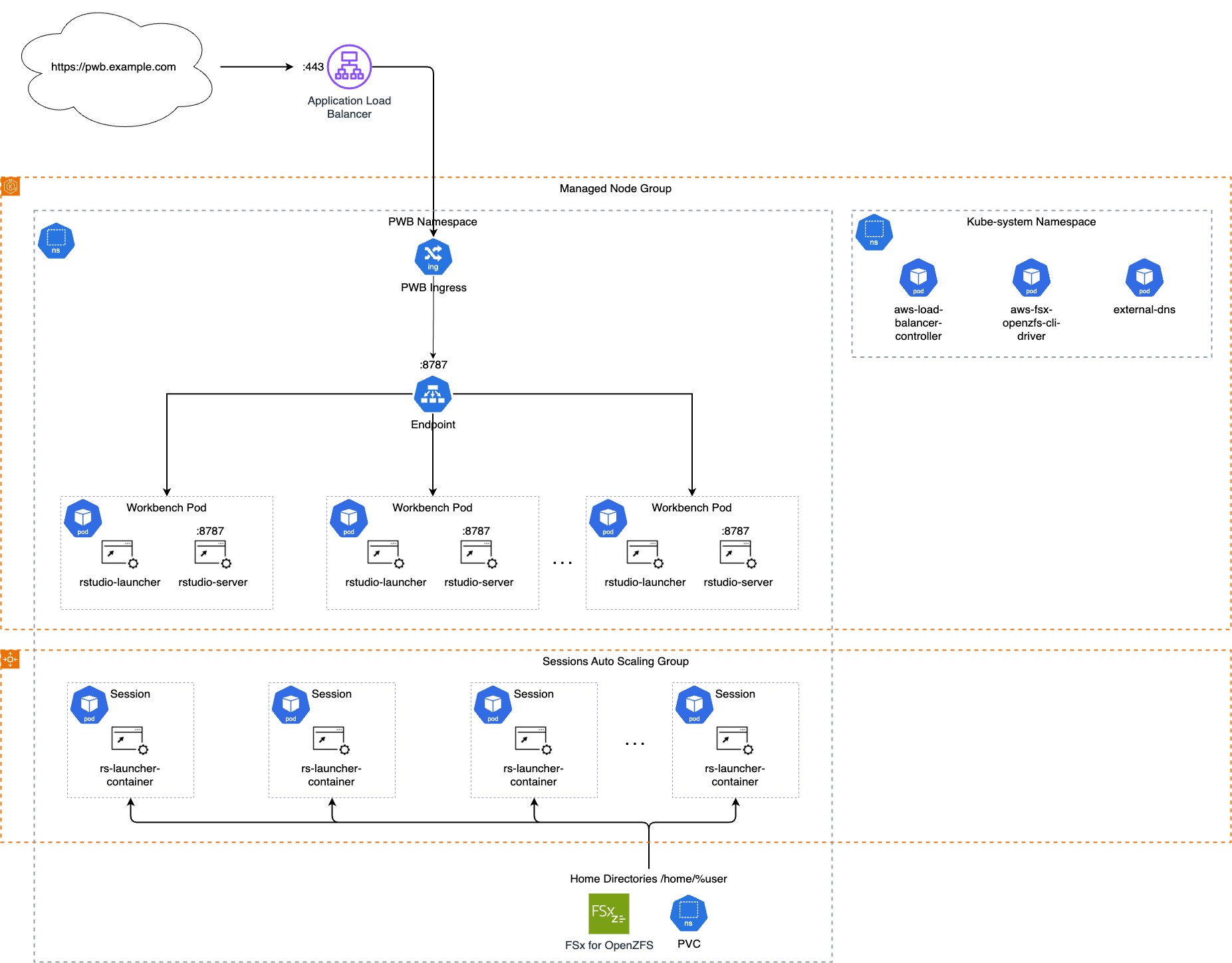
This architecture is using the AWS Load Balancer Controller to be able to configure the ALB by setting annotations in Helm. For more information about setting up the AWS Load Balancer Controller, see the AWS Load Balancer Controller GitHub repository.
The ExternalDNS Helm chart is used to create the DNS either from an ingress or a service within Kubernetes through annotations in Helm. For more information about setting up ExternalDNS in the EKS cluster, see this ExternalDNS tutorial.
Helm
Posit provides Helm charts that can be used to deploy Posit Workbench in a Kubernetes-based environment. The Helm charts offer a great deal of flexibility to allow administrators to control exactly how they would like their environment to be configured. This document does not cover all possible configuration options, but instead focuses on the settings that will enable administrators to get this environment up and running quickly.
If you wish to customize further, Posit provides examples of how to modify the Posit Helm charts in the Posit Helm Charts guide.
Container images
Posit Workbench container images are published under the posit/* organization on Docker Hub. The images are also available as ghcr.io/posit-dev/* on the GitHub Container Registry. The legacy rstudio/* images continue to be built during the transition to these new repositories.
If you deploy with the Workbench Helm chart, version 0.20.0 and later default to the new image repositories. Version 0.20.0 includes breaking changes that affect existing chart values, such as the removal of image.tagPrefix and a new default OS. See the Helm chart Migrating to Posit Images guide for the complete list of changes and migration steps.
To use this architecture, a minimum of three images will be needed: one for the Workbench nodes, one for starting sessions, and one for the session init container. Administrators may choose to create additional images for sessions that have different combinations of R, Python, or other dependencies. For more information about configuring multiple session images, see the launcher-sessions-container-image and launcher-sessions-container-images options in the Launcher Configuration chapter.
Posit provides the follow images as examples or starting points for use in containerized environments such as this architecture:
- posit/workbench (
ghcr.io/posit-dev/workbench) - posit/workbench-session (
ghcr.io/posit-dev/workbench-session)
For more information on using custom docker images for Posit Workbench sessions, see the Using Docker Images section of this guide.
The posit/workbench-session image does not contain the required Workbench session components necessary to run a session. It is intended to be used in conjunction with the posit/workbench-session-init init container image.
Posit also provides the posit/workbench-session-init image. Workbench automatically configures this image as the init container for the session Pod. The init container copies the components that run RStudio Pro, VS Code, and Positron sessions into the session Pod. The Workbench Helm charts enable this feature by default. See the Session init container section of the Job Launcher Configuration chapter for more information.
RDS
Configure a multi-AZ RDS instance with an empty PostgreSQL database for the Posit Workbench metadata. This RDS instance must be reachable by all Workbench hosts. In this setup, use two RDS instances, one in each of the two AZs, configured for auto-failover.
Autoscaling
This architecture enables autoscaling of the node group for sessions and Workbench Jobs through Karpenter. Autoscaling requires several conditions to function properly:
- Karpenter should configure node
taintsto prevent Pods that do not have matchingtolerationsfrom spinning up on autoscaling nodes. - Workbench should configure
tolerationson the launched sessions that match the Karpentertaintsin order to allow session Pods to spin up on the Karpenter nodes. - Workbench should configure node
affinityon the launched sessions, to ensure that the session Pods only spin up on the Karpenter nodes. - Workbench sessions should be configured with timeouts so they shut down after inactivity, which allows Karpenter to scale down unneeded nodes.
Node taints, tolerances, and affinities
Karpenter uses node taints to prevent Pods from spinning up on autoscaling nodes that do not have matching tolerations.
Workbench should configure launched sessions with tolerations that match the Karpenter taints. Additionally, these sessions need a node affinity for Karpenter nodes to ensure they spin up only on those nodes. Without node affinity, Workbench sessions may start on regular, non-autoscaling nodes instead. The following Helm configuration provides an example:
values.yaml
- 1
-
Node
affinitythat constrains session Pods to only spin up in Karpenter autoscaling nodes - 2
-
Tolerationsthat exactly match thetaintson the Karpenter nodes allows the sessions to spin up in Karpenter autoscaling nodes
See the Kubernetes documentation on Taints and Tolerances and Node affinity for more information.
Workbench session timeouts
For the best experience with autoscaling, we strongly recommend enabling session timeouts to allow autoscaling nodes to scale down. All Workbench session types support a suspension or exit timeout after a certain period of inactivity.
By default, inactive RStudio Pro sessions automatically suspend after two hours. Administrators configure the length of inactivity to trigger an RStudio Pro session to suspend via the session-timeout-minutes setting in the rsession.conf file.
By default, JupyterLab and Jupyter Notebook sessions are also configured to exit after a period of inactivity. See the Jupyter Configuration section for more information.
VS Code and Positron sessions use a session-timeout-kill-hours setting in the vscode.conf file or the positron.conf file, respectively, to terminate a session that has been inactive for a set amount of time. This setting enables a forced termination of the session, so pay close attention to the linked timeout configuration recommendations to prevent user data loss.
User authentication
It is possible to configure Posit Workbench with OpenID or SAML-based SSO for authentication, and to use an IdP for user provisioning. See the Authenticating Users and User Provisioning chapters respectively for more information.
FSx for OpenZFS
The FSx for OpenZFS volume will host user home directories, server configuration, and server state. The volume must be created before the Helm charts are deployed. Once the file system is created, a Persistent Volume (PV) can be added to the EKS cluster using a Helm chart. The Required Configuration section of the Posit Workbench Helm chart README includes instructions on how to configure a Persistent Volume Claim (PVC) for the EKS cluster.
Resiliency and availability
This architecture includes Posit Workbench in at least three replicas, configured in a load-balanced setup with each replica in one of the three Availability Zones, making it resilient to failures of one Pod or Availability Zone. RDS and FSx in two of those zones allow for backup and redundancy configuration within the service. RDS is configured with automatic failover.
This deployment is configured across three different AWS Availability Zones (AZ) to protect as much as possible against the loss of any single Availability Zone.