Databricks in RStudio Pro
Posit Workbench has a native integration for Databricks that includes support for managed Databricks OAuth credentials and a dedicated pane in the RStudio Pro IDE.
After starting a session with Workbench-managed credentials, the Databricks pane in RStudio will display available clusters and their metadata.
If the pane is not visible even if an administrator has already enabled Databricks, please confirm that all panes are visible, that the Databricks pane is in the expected pane section via Global Options, and then restart the session.
Databricks pane
The Databricks pane provides controls for Databricks clusters that your user is allowed to access in Databricks.

- Search for clusters by name or ID
- Sort by various cluster metadata
- Cluster state, includes active and inactive as well as transitory states
- Create a
sparklyrconnection to that cluster
- Start/Stop cluster
- Expand to show additional cluster metadata
After expanding a specific cluster, additional metadata is exposed.
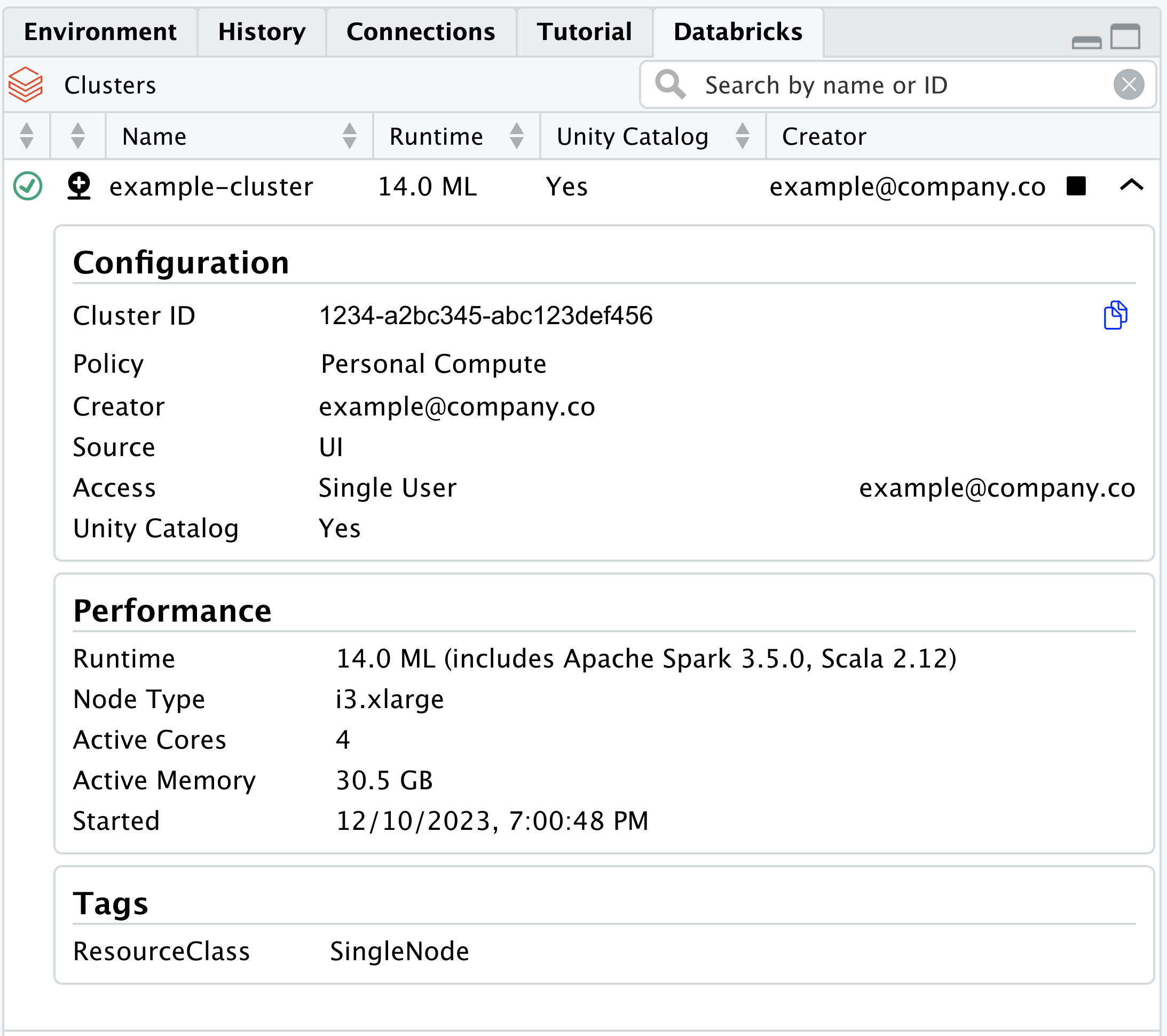
In this expanded view, there is also the ability to copy the Cluster ID for use in various scripts.
The Start/Stop Databricks cluster buttons are only functional if the host URL uses https. If this feature has been configured with http, then only viewing cluster metadata is allowed.
sparklyr integration
The sparklyr package is a R interface to Apache Spark™. Importantly, this package allows users to run distributed R code from Posit Workbench remotely inside Spark environments. Recent improvements to sparklyr have enabled deeper integration with Databricks, as outlined in Spark Connect, and Databricks Connect v2. In short, the sparklyr maintainers are using reticulate to interact with the Python API to Spark Connect. sparklyr extends the functionality, and user experience, by providing the dplyr back-end, DBI back-end, and RStudio’s Connection pane integration. In order to quickly iterate on enhancements and bug fixes, we have decided to isolate the Python integration into its own package. The new package, called pysparklyr, is an extension of sparklyr.
Setting up pysparklyr
The Databricks pane uses the sparklyr and pysparklyr R packages to create connections to Databricks clusters. When you create a new connection to a Databricks cluster, RStudio may prompt you to install or update sparklyr and pysparklyr to the minimum required versions. The minimum required versions for the 2023.12.0 release of Posit Workbench are pysparklyr v0.1.2 and sparklyr v1.8.4.
To run the initial pysparklyr::install_databricks() command in a RStudio Pro session, it is recommended to have at least 4 GB of memory. pysparklyr::install_databricks() will install Databricks Connect, which is mandatory for a remote connection, as well as various Python packages required for translating commands. Some of the packages are 100MB or larger, and the download process can temporarily consume significant memory.
Once pysparklyr is installed, follow the steps in the Initial setup section. After completing the setup steps for pysparklyr, see the cluster connection instructions to create a new connection from the Databricks pane.
To troubleshoot your pysparklyr configuration, review the Reported Problems section for more information.
Databricks cluster connections
While the Connections pane can be used to connect to Databricks clusters or SQL warehouses, the Databricks pane provides a direct integration to simplify connecting to a specific cluster via sparklyr.
If you installed sparklyr or pysparklyr manually (e.g., via the Packages pane or the RStudio console), please restart the R Session (i.e., Session > Restart R) before proceeding to create a new connection.
After confirming the cluster is active, click on the Connect with sparklyr icon to begin the simplified cluster connection wizard.

A pop-up window displays with the cluster ID prefilled. Then, choose to test the connection or click on Ok to form a connection to the Databricks cluster via sparklyr. This displays the active connection in RStudio’s Connection pane.

Using PATs
We strongly recommend using Workbench-managed Databricks credentials, but the Databricks pane can also be used with Databricks PATs (personal access tokens) by setting the correct environment variables.
For example, using an .Renviron file:
.Renviron
# Host must be HTTPS connection for starting/stopping clusters
DATABRICKS_HOST="Enter here your Workspace URL"
DATABRICKS_TOKEN="Enter here your personal token"If neither Workbench-managed Databricks credentials nor PAT environment variables are found, the Databricks pane will display a warning.